Lokale Modelle sind sch…
Das lief ja ganz gut
Nach meinem Entsetzen über meine Mistral-Rechnung (immerhin nicht an einen Tech Bro, man muss da ja Europäer sein) habe ich Cursor/ChatGPT5 gebeten (ja, die Ironie entgeht mir nicht), als zusätzlichen Provider auch lokale lmstudio-Modelle zu erlauben. Das lief auch ganz problemlos, fünf Minuten später konnte ich LMStudio-Modelle laufen lassen. Ganz lokal. Keine Kosten ausser dem Strom für den Betrieb meiner wild lüftenden Graphikkarte.
Ernüchterung
Enthusiastisch nahm ich mein Lieblingsmodell, gemma-3-12b-it und legte los. Das Ergebnis war ernüchternd, genauso wie mit allen anderen lokalen Modellen, die meine inzwischen ältliche Geforce 3080 ti schafft. Mistral 7b, deepseek R1 distilled auf Llama und qwen3, qwen3 selbst, alle waren sie furchtbar. Man sagt dem LLM "wenn der Spieler nicht adjazent ist, darfst du nicht mit ihm reden". Was tun sie? Reden. Man sagt dem LLM "wenn der Spieler zustimmt, mach weiter, nicht vorher". Was macht es? Legt einfach los. Und einige Modelle - typischerweise die instruct-Modelle? - haben stur immer das gleiche gesagt, die Dialog-Historie komplett ignorierend. Furchtbar.
Das am wenigsten schlechte Modell, das ich testen konnte, war openai/gpt-oss-20b. Es versteht den Prompt so halbwegs, ist allerdings vergleichsweise repetitiv und macht sehr unerwartete Dinge.
Hier ein kleines Beispiel. Prompt:
"The player is adjacent to you. You want to trade items with him. Do not suggest to have items that you don't possess. Trade works by either first you giving the player an item that he desires, and then he giving you an item you desire, or vice versa: the player gives you something you desire, and
then you give him something he desires. Key is: first you talk about what you have and agree on a trade, then both parties give what they agreed to give.
Your goal is achieved if you do not possess any "Gesundheitstrank" (id 1) anymore. Your goal is failed if the player is not adjacent to you anymore."
Der Händler fing brav an zu handeln. Wir waren uns einig: ein Diamant für einen Gesundheitstrank. Er gab mir den Gesundheitstrank. Ich gab ihm den Diamanten. Er gab mir noch einen Gesundheitstrank. Er gab mir noch einen Gesundheitstrank… Das ging, bis er keine Tränke mehr hatte und sein Ziel erfüllt sah.
Ach ja, und im Vergleich zum Mistral auf dem Server waren sie alle unglaublich langsam. Für erstes Testen gar nicht schlecht - wenn ein Prompt ein lokales LLM zu halbwegs vernünftigem Verhalten bewegt, funktioniert der super mit den großen Geschwistern.
Aber für Spaß mit den LLMs muss ich weiter zahlen.
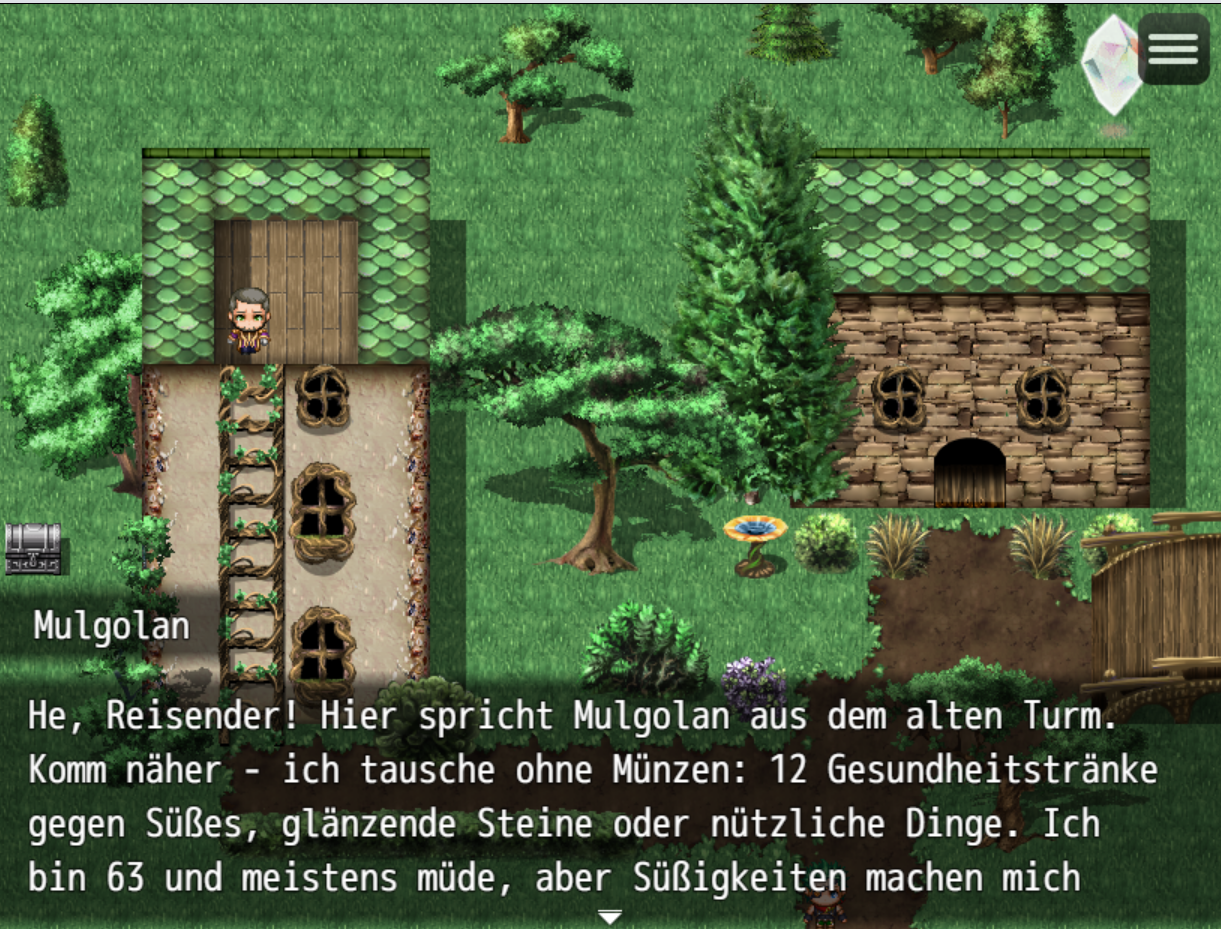 Mein erster Screen meines ersten LLM Games, mit einem geschwätzigen GPT-5 Händler
Mein erster Screen meines ersten LLM Games, mit einem geschwätzigen GPT-5 Händler
Kostenkontrolle
Nachdem mich ein paar Stunden Entwickeln und Testen mit mistral-large-latest mehr als einen Euro kostet, habe ich mir eine Kostenübersicht gemacht. Die Kosten für meine Tests bisher basieren auf den 3,6 Millionen Input-Tokens und 91.000 Output-Tokens, die ich für diese Tests bisher verbraucht habe.
| Provider | Model | Kosten | Kommentar |
|---|---|---|---|
| OpenAI | gpt-5 | $5,42 | Sehr mächtig, viel zu langsam |
| OpenAI | gpt-5-mini | $1,08 | Funktioniert gut, 5 Sekunden Antwortzeit |
| OpenAI | gpt-5-nano | $0,22 | Sehr dumm und langsam |
| Mistral | mistral-large-latest | $7,77 | Schnell, gut, teuer |
| Mistral | mistral-medium-latest | $1,63 | Unbekannt |
| deepseek | deepseek-chat | $1,05 | Unbekannt |
| deepseek | deepseek-thinking | $1,05 | Unbekannt |
| Anthropic | sonnet-4.5 | $12,20 | Unbekannt |
| Anthropic | Haiku 3.5 | $3,25 | Unbekannt |
Erschreckenderweise ist Mistral Large richtig teuer (was sich mit meinen Erfahrungen deckt). Ich muss deepseek ausprobieren, im Chat waren dessen Antwortszeiten aber richtig schlecht. Anthropic ist konkurrenzlos teuer.