Local models are sh…
That went quite well
After my horror at my Mistral bill (at least not paid to a Tech Bro – one must remain European), I asked Cursor/ChatGPT5 (yes, I’m aware of the irony) to also allow local lmstudio models as an additional provider. That went without any problems; five minutes later, I was able to run LMStudio models. Completely local. No costs other than the electricity for running my wildly ventilating graphics card.
Disillusionment
Enthusiastically, I took my favorite model, gemma-3-12b-it, and got started. The result was sobering, just like with all other local models that my now somewhat aging Geforce 3080 ti can handle. Mistral 7b, deepseek R1 distilled on Llama, and qwen3, qwen3 itself, they were all terrible. You tell the LLM, “If the player is not adjacent, you must not talk to him.” What do they do? Talk. You tell the LLM, “If the player agrees, go ahead, not before.” What does it do? It just goes ahead. And some models—typically the instruct models?—stubbornly always said the same thing, completely ignoring the dialogue history. Terrible.
The least bad model I could test was openai/gpt-oss-20b. It halfway understands the prompt, but it is comparatively repetitive and does very unexpected things.
Here’s a small example. Prompt:
"The player is adjacent to you. You want to trade items with him. Do not suggest to have items that you don't possess. Trade works by either first you giving the player an item that he desires, and then he giving you an item you desire, or vice versa: the player gives you something you desire, and then you give him something he desires. Key is: first you talk about what you have and agree on a trade, then both parties give what they agreed to give.
Your goal is achieved if you do not possess any "Gesundheitstrank" (id 1) anymore. Your goal is failed if the player is not adjacent to you anymore."
The merchant started trading diligently. We agreed: a diamond for a health potion. He gave me the health potion. I gave him the diamond. He gave me another health potion. He gave me another health potion… This went on until he had no more potions left and considered his goal achieved.
Oh yes, and compared to Mistral on the server, they were all incredibly slow. Not bad for initial testing—if a prompt gets a local LLM to somewhat reasonable behavior, it works great with the big siblings.
But for fun with LLMs, I still have to pay.
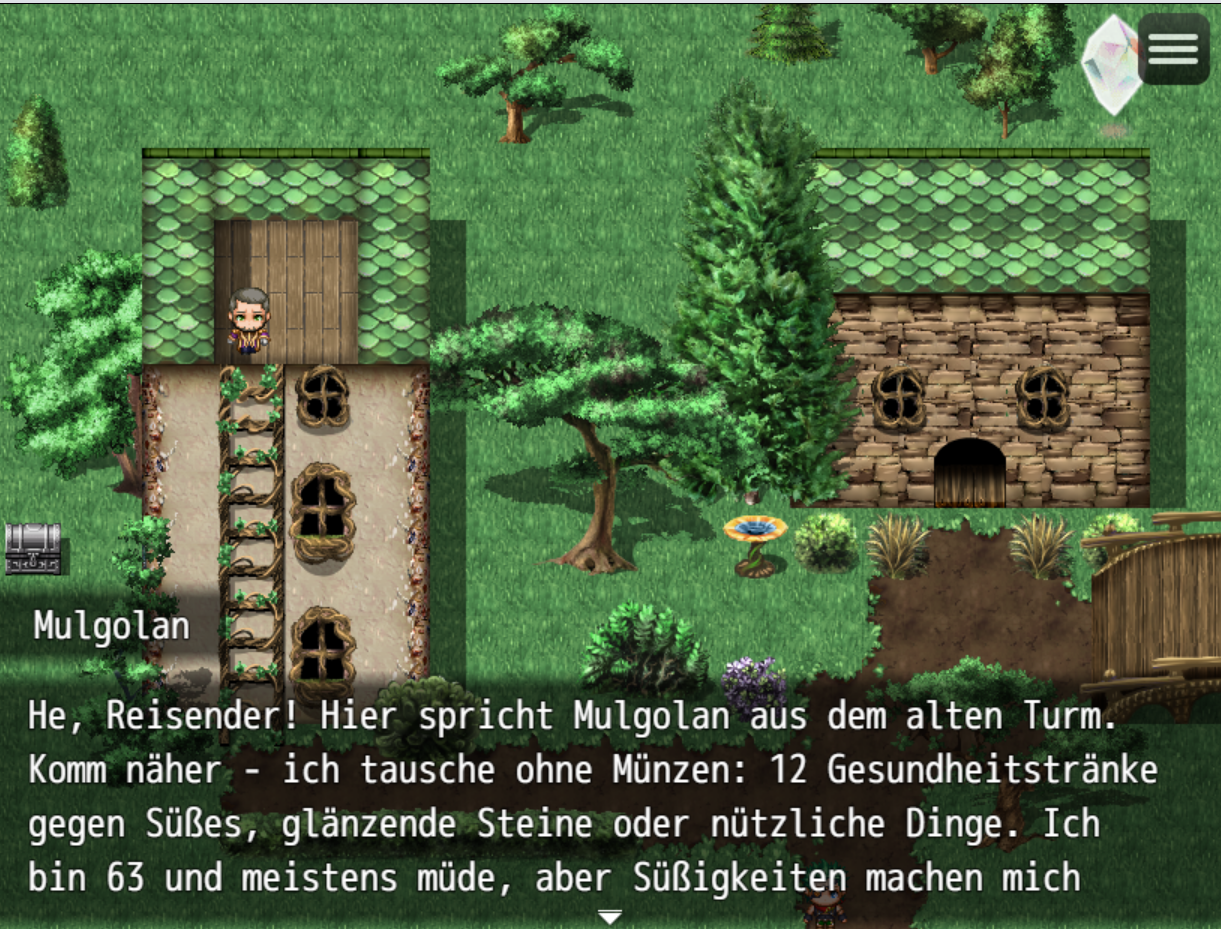 My first LLM game screen, with a very chatty trader powered by GPT-5
My first LLM game screen, with a very chatty trader powered by GPT-5
Cost control
After a few hours of development and testing with mistral-large-latest cost me more than one euro, I made a cost overview. The costs for my tests so far are based on the 3.6 million input tokens and 91,000 output tokens I’ve used in these tests so far.
| Provider | Model | Costs | Comment |
|---|---|---|---|
| OpenAI | gpt-5 | $5.42 | Very powerful, far too slow |
| OpenAI | gpt-5-mini | $1.08 | Works well, 5-second response time |
| OpenAI | gpt-5-nano | $0.22 | Very dumb and slow |
| Mistral | mistral-large-latest | $7.77 | Fast, good, expensive |
| Mistral | mistral-medium-latest | $1.63 | Unknown |
| deepseek | deepseek-chat | $1.05 | Unknown |
| deepseek | deepseek-thinking | $1.05 | Unknown |
| Anthropic | sonnet-4.5 | $12.20 | Unknown |
| Anthropic | Haiku 3.5 | $3.25 | Unknown |
Alarmingly, Mistral Large is really expensive (which matches my experience). I have to try deepseek; in chat, however, its response times were really poor. Anthropic is unrivaled in expense.